
Protocolo Análisis reproducible
protocolos
¿Cómo hacer un libro de códigos?
Keywords
codebook, reproducibilidad
IPO-reproducibilidad

Protocolo para flujo de investigación reproducible
Esta es una plantilla/protocolo de carpetas de proyecto basada en el protocolo TIER (Integridad de Enseñanza en Investigación Empírica). TIER “promueve la integración de principios y prácticas relacionadas con la transparencia y la replicabilidad en el entrenamiento en investigación de los científicos sociales”. (más información en https://www.projecttier.org/).
La implementación de la reproducibilidad en este tipo de protocolos se basa en generar un conjunto de archivos auto-contenidos organizado en una estructura de proyecto que cualquier persona pueda compartir y ejecutar. En otras palabras, debe tener todo lo que necesita para ejecutar y volver a ejecutar el análisis.
El protocolo IPO sigue la lógica de TIER, pero con algunas innovaciones:
intenta un modelo fácil de memorizar y relacionado con el flujo de trabajo de análisis (Input-Procesamiento-Output = IPO), donde el procesamiento se refiere a la preparación y análisis de datos.
agrega una carpeta “Input”, que tiene un alcance más amplio que la carpeta “Datos”original en TIER, pero también otras posibles entradas, como imágenes externas y archivos de bibliografía.
la carpeta de datos también se simplifica, incluyendo ahora solo una estructura “original” y “procesada”.
modifica los archivos a .md/.Rmd (archivos Markdown) /.Qmd (archivos Quarto) en lugar de .txt. Markdown es un lenguaje de texto con marcas mínimas de formato que luego se pueden convertir a otros formatos como pdf y / o html (por ejemplo, cuando se usa R / Rmarkdown / Quarto). Pero, en el fondo, son simples archivos txt con solo otra extensión.
Archivos y estructura de carpetas
├── input: información externa como datos, imágenes, .bib:
| ├── data-orig: archivos de datos originales y metadatos disponibles
| ├── data-proc: archivos de datos procesados
│ ├── imagenes
│ ├── bib: archivos de bibliografía
│ ├── prereg: archivos de pre-registro si están disponibles
|
├── procesamiento:
│ - preparacion.qmd
│ - analisis.qmd
|
├── output: tablas, gráficos y otras salidas del procesamiento.
│ ├── graphs
│ ├── tables
|
- readme.md : archivo general de introducción
- paper.qmd / paper.html / paper.pdf: el artículo/paperVersiones de IPO
| Plantilla | Descripción | Software | Documentos dinámicos | Control de versiones | Enlace |
|---|---|---|---|---|---|
| IPO-base | Orientado a cualquier software o paquete estadístico. Emplea la estructura de carpetas del protocolo. | Cuaquiera | NO | NO | IPO base |
| IPO-R | Orientado a usuarios de R. Emplea la estructura general de carpetas y posee énfasis en la reproducibilidad de resultados (tablas, figuras, etc) | R | SI | NO | IPO R |
| IPO-Rgit | Mantiene la misma estructura básica, esta versión es una actualización para aprovechar todas las herramientas de reproducibilidad, colaboración y publicación ofrecidas por los entornos de trabajo Quarto / Github. | R+Git | SI | SI | IPO R+Git |
Principios básicos
orden: trabajar pensando en alguien que no esté familiarizado con el proyecto pueda entenderlo y reproducirlo sin mayores instrucciones que la referencia a este protocolo y otra información que esté en el archivo readme.md. O piense en usted dentro de 5 años: ¿podrá comprender y reproducir esto?
comentar los códigos: registrar brevemente los motivos de cualquier decisión
el código de preparación debería comenzar cargando los datos originales y terminar guardando los datos procesados en la carpeta correspondiente (proc).
El flujo de trabajo asociado a estos principios se presenta en el siguiente esquema:
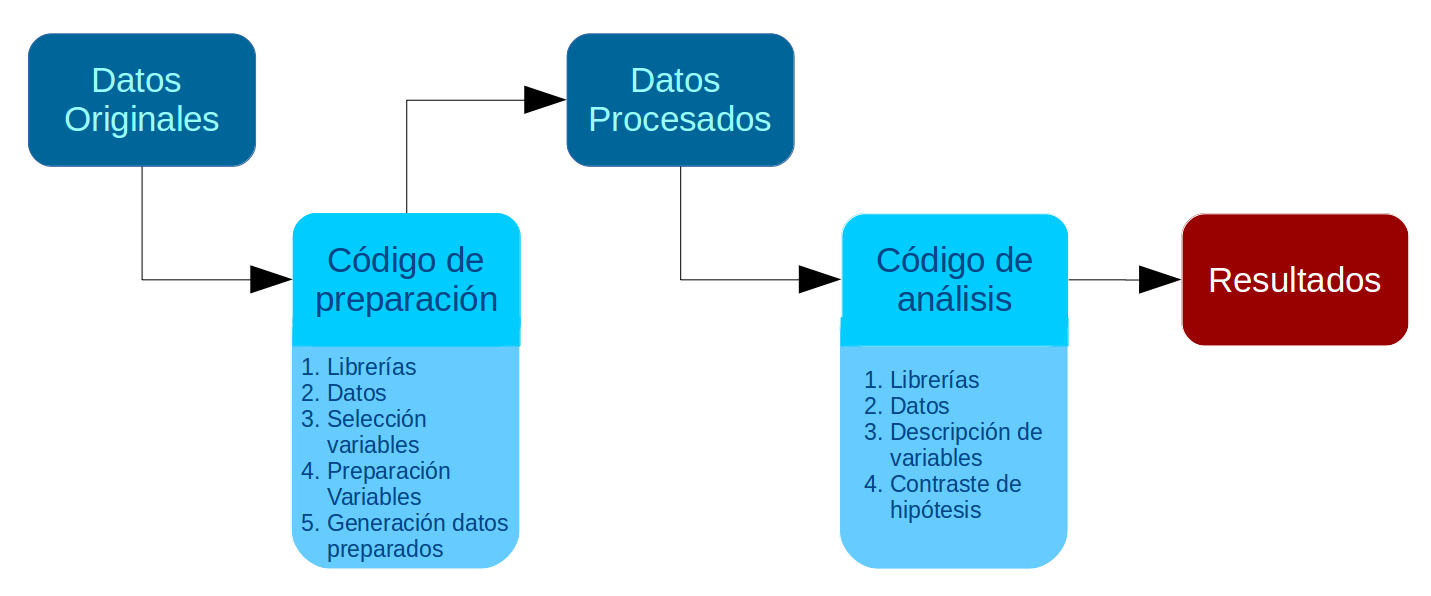
Ejemplo
Un ejemplo mínimo para probar la implementación del protocolo se puede bajar aquí
¿Quieres comentar o tienes alguna duda?
Puedes dejar tus comentarios y dudas sobre el Protocolo IPO en nuestro foro. De todas formas puedes contactarnos